
FaceHarmony — a generative AI product shipped end-to-end
A solo-built consumer AI platform spanning model training, GPU inference, mobile apps, payments, and cloud operations. Built as a real production system with real users, real infrastructure, and full operational ownership.
Why active development stopped
FaceHarmony reached a technically robust, stable production state and is now in maintenance — no active feature development, ongoing operations, cost, and security upkeep only. Active product development was paused as a deliberate decision, for reasons described below.
- A production-first mindset, applied too early. The system was hardened for scale, security, and invitations before customer demand had been validated end-to-end. The infrastructure was ready to grow; the user volume was not. That sequencing is the lesson.
- Distribution, not engineering, was the gap. Sustainable growth required professional consumer-app marketing capabilities that the project's solo-builder structure could not absorb at an acceptable risk profile.
- Rapid advances in foundation image models compressed the moat around person-specific fine-tuning. Identity-preserving image transformation became dramatically more accessible. Active development was intentionally paused, and the underlying engineering focus was redirected toward higher-leverage work in regulated medical AI.
Production capabilities
- Person-specific generative image models with reproducible training and curation pipelines.
- Style libraries and quality controls validated across many subjects.
- Production cloud architecture: GCP-based, with batched GPU training and an event-driven generation queue.
- Cross-platform mobile app — uploads, payments, galleries, secure delivery.
- Token-based payments and an invitation system designed for controlled growth.
- Hardened auth, App Check, and abuse-prevention across the entire stack.
- Cost discipline on GPU spend that survived multiple price changes from upstream providers.
- Operational runbooks, monitoring, and incident response written for one-person on-call.
System Design
Production Architecture
FaceHarmony's backend separates personalized model training — a computationally expensive, long-running workload — from on-demand image inference. These two concerns run on independent GPU worker pools, communicate through an async event queue, and are coordinated by a stateless Cloud Run API that holds no GPU state. Clients receive an immediate response; GPU capacity is allocated to actual work.
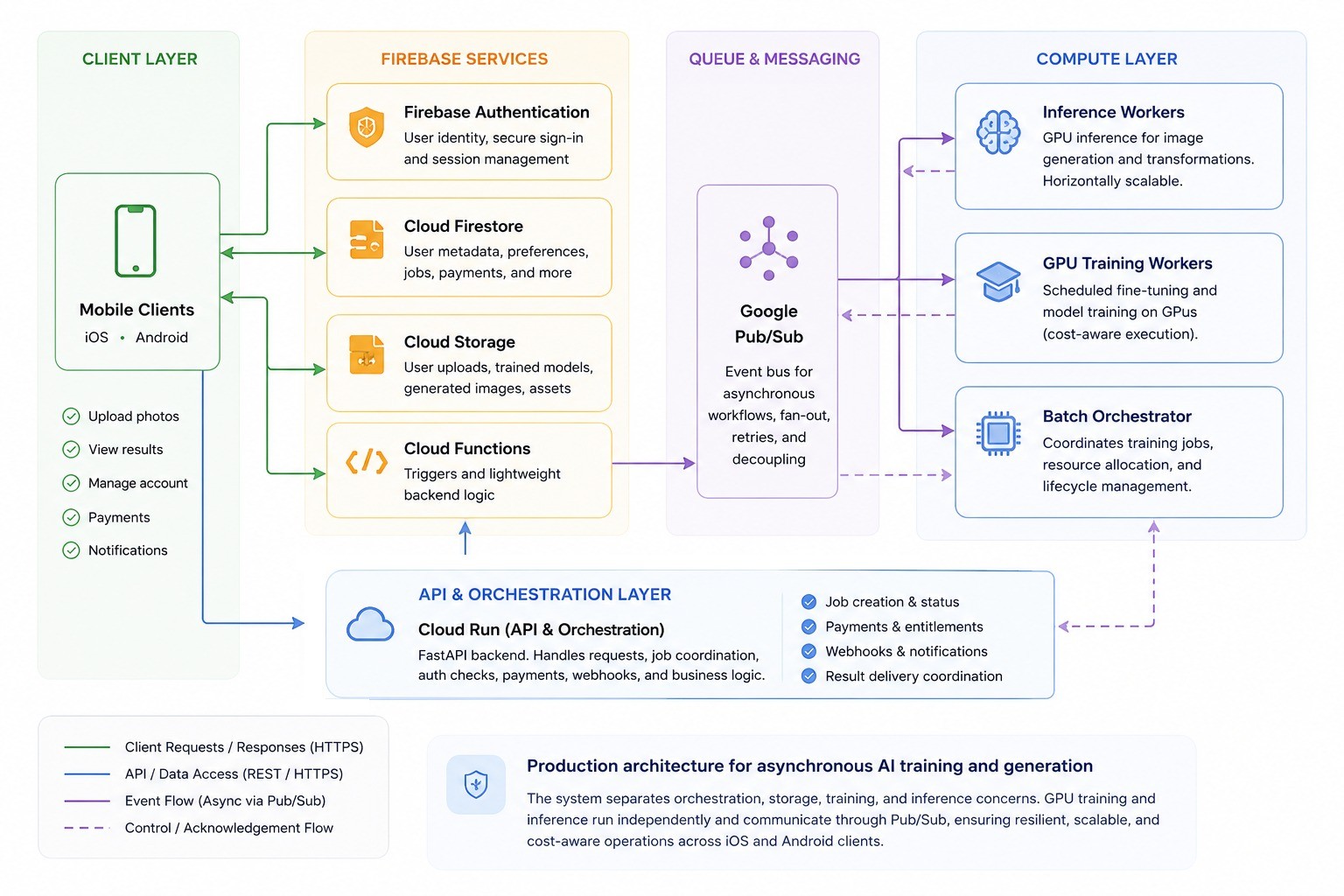
Architecture Summary
- All client communication is HTTPS. iOS and Android clients interact with Firebase SDKs for auth and storage, and with the Cloud Run API for business logic. No direct client-to-worker paths exist.
- The API tier is stateless and GPU-free. Cloud Run (FastAPI) validates tokens, writes job records to Firestore, and publishes Pub/Sub messages. Every compute job is asynchronous — the API responds before any GPU work begins.
- Google Pub/Sub decouples all compute from the API. Training requests, inference requests, and worker completion signals are all queue messages. Retries and dead-letter handling are managed by the queue; workers do not implement their own retry logic.
- Training and inference run on separate worker pools. Training workers are provisioned per batch, fine-tune a LoRA adapter against user-uploaded photos, persist the checkpoint to Cloud Storage, and are torn down. Inference workers are independently scaled, persistent across requests, and load user-specific LoRA adapters against a shared base model at request time.
- The Batch Orchestrator manages training lifecycle exclusively. It schedules jobs, allocates GPU capacity, enforces per-job timeouts, and emits control signals. It has no role in inference scheduling.
- Cloud Storage handles all binary I/O. Clients upload directly via short-lived signed URLs; the API never proxies photo or image data. Uploads, checkpoints, and generated output are stored under separate path prefixes to support clean per-model deletion.
- Firestore is the client-facing state bus. Job status transitions written by workers propagate to clients through Firestore real-time listeners. No polling, no persistent server-side connection.
- Firebase Authentication handles identity end-to-end. Every API request carries a Firebase JWT verified server-side before any Firestore or Pub/Sub interaction. The API issues no tokens of its own.
Operational Design
Training vs. inference separation
Training and inference have different hardware profiles, different latency requirements, and different scheduling patterns. Combining them on shared infrastructure would either strand GPU capacity between training jobs or create contention against latency-sensitive inference requests. The separation is an explicit cost and reliability decision.
Cost management
Training is the dominant GPU expense. The Batch Orchestrator schedules jobs to run during off-peak windows using preemptible capacity where available. Hard per-job timeouts prevent stalled training from holding GPU slots. Inference workers are not provisioned during dedicated training windows unless priority requests are actively queued.
Scalability
Cloud Run scales to zero between traffic bursts. Inference worker count scales on Pub/Sub queue depth — proportional to actual demand rather than a time-based estimate.
Reliability
Job state transitions are written to Firestore before the next step begins. If a worker crashes, the unacknowledged Pub/Sub message is redelivered to the next available worker. Messages that exhaust retries land in a dead-letter topic for inspection.
Abuse prevention
Token balances are validated by the API before any Pub/Sub message is emitted. Payment receipts are verified server-side against Apple and Google receipt validation APIs before tokens are credited. Signed upload URLs are scoped to a single operation with short expiry windows.
What this work demonstrates
End-to-end generative AI delivery
from model training and data pipelines to production inference, payments, and mobile deployment.
Single-builder ownership across ML systems, mobile engineering, cloud infrastructure, security, observability, and operational support.
Production-grade operational discipline including reproducible training, hardened authentication, abuse prevention, cost-aware GPU orchestration.
Discuss Your Next System or Deployment
Technical discovery, production engineering, and deployment-focused collaboration for intelligent systems, computer vision, and medical imaging workflows.
No obligation — just a focused technical conversation